1、项目背景
(1)人工智能产业加速发展,基础数据服务业规模不断提升
随着互联网、云计算、物联网以及穿戴设备的发展,数据要素价值不断释放,数字化转型成为大势所趋。人工智能作为数字经济发展的底层核心技术之一,成为数字经济发展的重要战略抓手。
2022 年底 ChatGPT 的出现,掀起又一波人工智能发展热潮,以无监督学习模式为代表的预训练+人类反馈强化学习所构成的大模型技术路线的落地意味着人工智能开启发展新范式,基础模型能力通过预训练及基于人类反馈的强化学习得到不断解锁,以解决海量开放式任务。
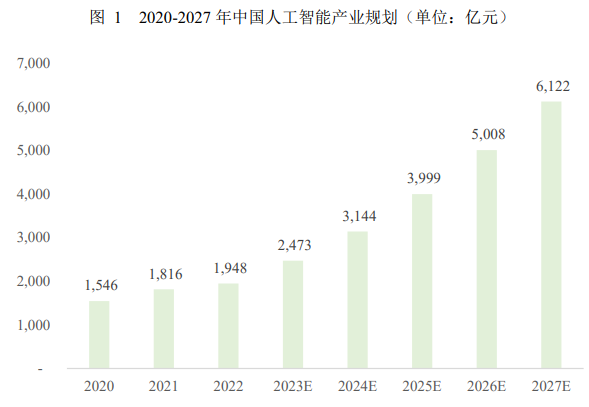
根据艾瑞咨询数据,2022 年中国人工智能产业规模为 1,948 亿元,预计 2027年市场规模将达到 6,122 亿元,年复合增长率为 25.6%,主要与智算中心建设以及大模型训练等需求拉动的 AI 芯片市场、无接触服务需求拉动的智能机器人及对话式 AI 市场等快速增长相关。
数据来源:艾瑞咨询
在人工智能产业链中,算法、算力和数据共同构成技术发展的三大核心要素。过去十年,人工智能产业以算法为中心,随着算法趋于开源,数据的重要性愈发凸显。在人工智能模型从技术理论到应用落地的过程中,需要依赖大量的训练数据,相较于以模型为中心的训练方法,以海量数据为中心的训练方法能够提升模型推断结论的可靠性。
万亿 GB 量级的数据随着互联网、云计算、物联网、大数据等发展源源不断地产生,但数据质量参差不齐,对海量的复杂数据进行深入挖掘、输出,进而激活和释放数据的深层价值也成为数据市场的发展重点。根据德勤数据,2022 年中国人工智能基础数据服务市场规模为 45 亿元,2027 年规模将达到 130-160 亿元,年复合增长率为 23.6%-28.9%。
(2)大模型技术发展带来 AI 范式变革,催生新型数据服务需求,进一步提升数据市场空间
人工智能大模型由于其强大的通用性能以及泛化能力正在加快人工智能发展路径,在大幅增强人工智能体验感的同时降低再开发门槛,使得人工智能产业具备在各实体产业快速落地发展的潜能。
随着大模型技术的发展,算法训练对数据的依赖程度逐渐加深,催生了新的数据需求和新的数据服务模式。一方面,数据的质量以及数据清洗的工程化能力会显著拉开大模型预训练阶段的效果差距;另一方面,预期更多模型将采用类强化学习模式来进行特定领域或特定方向上的优化迭代,以使得机器能够以更加接近于人类期望的方式提供答案输出。未来数据处理将不再局限在传统的有监督学习下的定向采集与精细化标注,而将叠加数据规模化获取、清洗以及类强化学习等方向。
此外,随着深度学习技术的不断突破,人工智能发展已经进入 2.0 时代,AI技术与传统产业的融合将成为数字经济时代的新发展趋势。大模型算法训练需求正逐渐从通用基础能力建设向垂直领域拓展,数据需求向专业化方向发展。目前,AI 技术在金融、医疗、工业等传统行业中的渗透率和应用不断提升,展现出可观的商业价值和较强的发展潜力。为加速实现 AI 产业化落地,行业将衍生出更多垂直场景的数据需求,大模型将通过不断学习各个专业领域的行业高质量数据,实现更广阔的垂向拓展。
与此同时,国内科技互联网巨头纷纷布局多模态大模型,基于公开数据及自身特有数据训练多模态大模型,多模态数据集需求快速提升,多模态成为大模型时代下新发展范式。
(3)各地推动数据基础制度建设,数据要素市场迎来新发展机遇
近年来,我国数字经济蓬勃发展,数据要素因具有基础性战略资源和关键性生产要素的双重属性,相关市场规模持续增长。尤其在《中共中央、国务院关于构建数据基础制度更好发挥数据要素作用的意见》出台后,我国系统性布局了数据基础制度体系的“四梁八柱”,加速了数据流通交易和数据要素市场发展,进一步推动了公共数据、企业数据、个人数据合规高效流通使用。为更好响应中央号召,北京、上海、广州、深圳、杭州等地数据政策陆续出台,逐步构建了多层次、多元化数据要素市场生态体系。
以北京为例,《北京市促进通用人工智能创新发展的若干措施》和《关于推进北京市数据专区建设的指导意见》指出,北京市要加快建设“数据基础制度先行先试示范区”(以下简称“先行先试示范区”),探索打造数据训练基地,归集高质量基础训练数据集,推动数据要素高水平开放,提升本市人工智能数据标注库规模和质量,并建设针对重大领域、重点区域或特定场景建设专题数据区域,吸纳市场主体和数据、技术、资本等多元要素参与。
北京市陆续出台的多项文件旨在打破数据壁垒,推动数据融合利用,加快推动公共数据开放,促进数据要素流通,激发数字市场创新活力,释放和发展数字化生产力,打造多层级数据要素市场,成为具有竞争力和影响力的数字产业集群。按照“政府引导、市场运作、创新引领、安全可控”的原则,“先行先试示范区”有望成为国际领先的数据要素高效流通核心枢纽。
根据国家工信安全发展研究中心数据,2022 年我国数据要素市场规模为 904亿元,预计到 2025 年将达到 1,749 亿元左右,2020 年-2025 年年复合增长率为26.26%,数据要素将成为赋能中国数字经济发展的重要驱动力量。
(4)我国拥有海量数据资源,但数据质量仍面临严峻挑战,成为行业亟待解决的问题
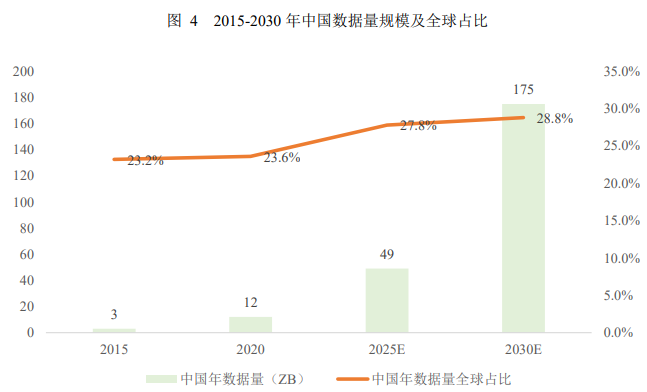
我国各行业数据资源较为丰富,根据艾瑞咨询数据,2015 年-2030 年中国数据量规模由 3ZB 将增长至 175ZB,预计 2030 年中国数据量约占全球的 28.8%,年复合增长率约为 31%。
数据来源:艾瑞咨询
虽然中国数据资源丰富,但由于数据挖掘不足,以及大量数据无法在市场上自由流通等原因,优质中文数据集仍然稀缺。以 ChatGPT 为例,其模型训练数据中,中文数据来源不足千分之一。目前,国内头部科技企业主要基于公开数据集以及自身特有的数据进行大模型训练,但由于中文优质数据质量以及数据资源的制约,国内大模型的能力与以 ChatGPT 为代表的国际大模型相比仍存在一定差距。
国内缺乏高质量数据集的主要原因包括当前国内数据挖掘和数据治理的力度不足、资金投入较大;数据流通与数据安全保障措施不够健全;国内市场缺乏开源意识,大量数据无法在市场上自由流通;国内相关公司成立较晚,数据积累较少;学术领域中文数据集受重视程度低以及国产数据集市场影响力及普及度较低等。
从原始数据到可被应用的数据集产品,需要经历数据集结构设计、数据获取、数据处理(包括数据清洗、数据标注/优化等)等过程,以形成可供使用的优质数据集,国内数据服务市场的发展有助于缓解中文数据集数量不足和质量欠佳等问题。
2、项目基本情况
大模型训练数据具备如下三个特点,具体而言:
一是数据规模大,根据DeepMind 论文《TrainingCompute-Optimal LargeLanguageModels》,模型参数规模预训练数据的 Token 数最佳比例在 1:20,要充分训练一个千亿规模的模型,至少需要 TB 级的训练数据;
二是数据质量高,在模型训练之前,需要依赖专业团队对数据进行清洗等预处理,防止数据中的噪声对模型的训练产生不良影响,在一些特定的任务中,还需根据不同目的对模型训练数据进行过滤;
三是数据类型丰富,多领域的数据是大模型具备通用 AI 能力的关键,需从不同渠道收集各种训练数据,包括各类垂直领域数据、多语言数据、翻译类平行语料、多轮对话数据、代码库和题库等。
基于以上特点,本项目拟建设 AI 大模型训练数据集,即生产用于通用型、及各种垂直领域大模型训练的海量、高品质数据集。本项目拟购置办公楼作为建设大模型训练数据研发生产基地,并购置数据采集、数据处理、数据存储和办公等软硬件设备,利用海量、高质量、多样化的公共数据资源、社会数据资源和稀缺性数据源,通过数据集设计、数据采集/获取、清洗/分类/标准化、标注/优化、评测等全流程的任务执行进行高质量大模型训练数据集建设。
本项目将充分利用“先行先试示范区”在基础制度、数据供给等方面的先行先试政策,采用多元化的方式获取大规模原始数据;利用工程化的数据处理技术进行预训练阶段的数据清洗;采用人类反馈强化学习模式,基于微调和奖励模型训练的方法,以人类撰写少量的典型问题和标准答案与深度学习阶段基础性标注相结合的模式,生产出市场适用性较强的大模型训练数据集。
本项目建成后,将提供可供大模型训练和评测的不少于 10 个品类的专业数据集,显著提升行业内面向大模型训练数据集的类别和质量,协助实现公共数据、社会数据等各类高价值数据资源汇聚,实现基于大模型通用能力和垂直领域数据的训练学习。本项目的数据集产品具体可分为三大类:
(1)通用及特定垂直领域的大语言模型训练数据集,包括但不限于:①中文大模型预训练语料数据集(含通用场景、特定场景、对话场景、指令集等);②多语言大模型预训练语料数据集(含通用场景、对话场景、指令集等)。
(2)多模态大模型训练数据集:可应用于多语言图文大模型训练、多模态数字人训练、多语种语音大模型训练、全场景自动驾驶大模型训练等场景的跨模态数据集。
(3)大模型评测数据集:可应用于大模型的能力、任务、指标等方面的评测。
3、项目建设必要性
(1)本项目建设是响应国家建立数据基础制度,落实北京建设“先行先试示范区”的必然选择
党的十八大以来,习近平总书记屡次强调建设数字中国以及构建数据要素的重要性,并明确指出数据是新的生产要素,是基础性资源和战略性资源,也是重要生产力。为进一步推动国家数字经济发展,发挥数据要素在经济发展中的重要价值,我国推出《中共中央、国务院关于构建数据基础制度更好发挥数据要素作用的意见》,从顶层设计角度,在数据产权、流通交易、收益分配、安全治理等方面构建了数据发展的基础制度和规划纲要,以促进数据合规高效流通使用,充分发挥中国海量数据规模和丰富应用场景优势,赋能实体经济,激活数据要素的潜能。
北京市则率先开展国家数据基础制度“先行先试示范区”建设, 2023 年 5 月发布的《北京市促进通用人工智能创新发展的若干措施》指出,充分发挥政府引导作用和创新平台催化作用,整合创新资源,加强要素配置,营造创新生态,提升高质量数据要素供给能力,归集高质量基础训练数据集。
公司作为人工智能基础数据服务领域具有较强国际竞争力的国内头部企业,有义务和责任积极响应北京建设“先行先试示范区”的号召,通过本项目的实施有效助力数据要素市场培育,推动数字经济创新发展,为北京市加快建设全球数字经济标杆城市提供助力。
(2)本项目建设是践行国家规范生成式人工智能产品要求的重要举措
生成式人工智能产品因其复杂性可能带来社会风险、技术伦理风险、企业商业秘密和个人信息泄露风险、虚假信息风险、知识产权侵权风险及其他潜在风险。为了更好地促进生成式人工智能技术健康发展和规范应用,国家网信办于 2023年 4 月出台了《生成式人工智能服务管理办法(征求意见稿)》,该办法从内容合规、数据来源合法性、知识产权及商业秘密保护、虚假信息防范等方面,对生成式人工智能产品提出了全方位的合规要求。
该办法明确提出,“提供者应当对生成式人工智能产品的预训练数据、优化训练数据来源的合法性负责”、“能够保证数据的真实性、准确性、客观性、多样性”、“生成式人工智能产品研制中采用人工标注时,提供者应当制定符合本办法要求,清晰、具体、可操作的标注规则,对标注人员进行必要培训,抽样核验标注内容的正确性”、“提供者应当根据国家网信部门和有关主管部门的要求,提供可以影响用户信任、选择的必要信息,包括预训练和优化训练数据的来源、规模、类型、质量等描述,人工标注规则,人工标注数据的规模和类型,基础算法和技术体系等”。
根据前述规定,数据获取、数据处理的高标准意味着数据获取难度及处理成本将大幅增加,以预训练阶段为例,由于大量数据来源应合法合规,需投入大量成本完成数据获取。因此,出于成本与数据集质量的平衡性考量,在大模型训练中,大模型厂商通常会选择与专业的第三方数据集厂商合作,由专业第三方提供的合规、高质量数据集或相关解决方案将成为践行国家规范生成式人工智能产品要求的重要举措。
(3)本项目建设是支撑大模型训练,提升大模型输出能力的有效方式
随着人工智能应用场景日益丰富、产品智能化要求的不断提升,数据需求逐渐向海量、高质量、多元化方向演进。从自然数据源简单收集、获取的数据资源,通常无法直接满足大模型的训练需求,需经专业化的数据分类设计、清洗、加工处理,形成相应的工程化数据,以供大模型训练使用。一般而言,符合大模型训练标准的数据需具备质量高、规模大、样本丰富等三个特点。
首先,海量具有无毒害性、公平性等高质量特征的数据集能够提高模型效果(例如,精度与可解释性),并且减少收敛到最优解的时间;其次,在强化学习阶段,原始数据由于存在信息量低、含有噪声或需补齐等问题,使用前需要进行数据对齐等诸多微调操作,优秀的指令数据集能够帮助大模型更好的泛化适配更多下游任务。再次,数据丰富程度能够显著提高大模型的泛化能力,减少过拟合情况的发生,达到更优的模型效果。
当前国内数据资源虽然丰富,但优质的中文大模型训练数据仍然稀缺,中文大模型训练数据数量与质量,受国内产业环境、数据积累程度、数据运营生态等因素影响,与全球领先国家仍存在一定差距,使得国内大模型难以拥有足够专业的数据资源进行训练。本项目通过提供覆盖预训练、强化学习及应用拓展阶段的海量、高质量专业数据集,更好的支撑大模型训练,提升大模型输出能力。
(4)本项目建设符合公司“夯实传统业务,探索新型业务”的战略目标
为更好实现公司业务发展战略,公司在保障人工智能基础数据业务稳健发展的同时,不断探索寻求新的业绩增长点。如前文所述,数字经济时代下,数据要素市场发展前景广阔,大模型等人工智能技术已成为国家科技发展的重要抓手,但国内数据仍存在数据质量差、各领域数据无法流通等问题制约了人工智能行业的发展。公司将基于过往的数据服务经验,结合行业前沿需求,积极拓展大模型训练数据服务领域,力争将大模型训练数据等创新业务打造成为具有潜在高增长价值的新型业务板块。
4、项目建设可行性
(1)数据要素政策红利持续释放,利好政策支撑数据服务产业发展
国家高度重视数字经济发展,而数据要素作为数字经济深化发展的核心引擎重要性更加凸显,多项政策密集出台为本项目的顺利实施提供了政策保障。
(2)大模型驱动人工智能发展全面提速,新型训练数据服务具备市场空间
随着人工智能大模型技术的发展,行业对数据的依赖程度逐步加深。本项目产出的大模型训练数据集拟显著改善大模型训练中,包括预训练数据获取、清洗、强化学习调优、对齐、应用阶段评测等各个阶段的数据规模与质量问题。
该类数据集将有效提升行业内面向大模型训练数据集的类别和质量,并保障数据来源与处理合法合规,也将发挥规模化运营的优势,平衡数据集成本与市场效益,实现基于大模型通用能力和垂直领域数据的支撑和训练学习,协助实现公共数据、社会数据等各类高价值数据资源汇聚。本项目与公司多年发展中持续运行的商业模式相契合,市场空间广阔,具备可行性。
(3)公司具备较强的数据生产及服务等综合能力,为项目实施奠定基础
①公司拥有深度学习的技术储备,为新业务提供技术支撑
自 2005 年以来,公司始终致力于为 AI 深度学习提供算法模型开发训练所需的专业数据集,提升模型推断结论的可靠性。公司现已积累较为完备的综合性、一体化数据处理平台及工具体系,覆盖智能语音、计算机视觉、自然语言等全业
态领域,可服务于市面上绝大多数数据处理需求。截至 2022 年 12 月 31 日,公司已取得 31 项专利和 163 项计算机软件著作权,覆盖平台工具开发、算法研究、产品设计等多方面。此外,公司还设置了 AI+研发部门,前瞻性挖掘和布局新兴市场需求,抢占市场先机。
公司现有的深度学习模型数据主要是通过定向采集、精细化标注实现,即通过打标签的方式将数据类别、位置、性状、结构等信息进行精细化标注,提供给深度学习模型进行学习。大模型的训练则需要以海量数据为基础,对数据的缺失值、异常值、格式等进行清洗处理,通过高效的、多元化的、专业的人类反馈不断强化和优化模型训练,提升大模型与用户交互过程中的反馈质量。公司可将现有业务的技术储备复用到大模型业务中,将深度学习数据集生产中积累的能力延伸使用至大模型数据集生产。
②公司具有丰富的、多领域数据集产品生产经验,为新业务奠定经验基础
公司的标准化数据集产品是公司区别于众多竞争对手以定制化服务为主的特有商业模式,在多语种及多音色语音数据集和发音词典、动作捕捉等多模态数据集、以及多语种 OCR 和手写体数据集等方面积累了丰富的标准化产品资源。
截至 2022 年 12 月 31 日,公司拥有智能语音数据集产品储备 927 个、计算机视觉数据集产品储备 125 个、自然语言数据集产品储备 282 个。经过多年积累,公司已向下游客户提供了累计约 6,000 次/个定制或标准化训练数据集,覆盖个人助手、语音输入、智能家居、智能客服、机器人、语音导航、智能播报、语音翻译、移动社交、虚拟人、智能驾驶、智慧金融、智慧交通、智慧城市、机器翻译、智能问答、信息提取、情感分析、OCR 识别等 19 类创新应用领域,构建出独具特色的训练数据资源及服务能力集群,公司在标准化数据集产品的能力获得市场认可,并为后续标准化数据产品生产奠定扎实基础。
③公司已经服务全球众多科技巨头,为新业务拓展提供客户资源基础
公司自 2005 年成立以来,始终致力于挖掘行业客户需求,解决客户痛点,通过在智能语音、计算机视觉、自然语言等领域的技术积累,获得全球众多客户认可,包括阿里巴巴、腾讯、百度、科大讯飞、海康威视、字节跳动、微软、亚马逊、三星、中国科学院、清华大学等全球主流企业、教育科研机构以及政企机构。截至 2022 年底,公司累计服务客户数量已达到 810 家。公司的存量客户与新业务的客户重合程度较高,且存量客户群中的部分头部企业已输出或计划输出其大模型产品与服务,为公司该项新业务拓展提供了客户资源基础。
④公司历来重视数据安全能力及合规体系建设,为新业务提供合规保障
公司一直以来非常重视数据安全能力及合规体系建设,数据安全管理工作获得市场认可。资质方面,公司拥有 ISO27001 信息安全管理体系认证、ISO27701隐私信息管理体系认证、国家信息安全等级保护三级认证、北京市规划和自然资源委员会行政许可乙级测绘资质等。
行业参与方面,公司入选中共中央网络安全和信息化委员会办公室“人工智能企业典型应用案例”,成为中国信通院数据安全推进计划成员单位,董事兼副总经理李科入选该计划数安智库专家,发表《AI 训练数据安全管理实践》等文章,为人工智能领域数据安全管理建言献策,并荣获数安智库 2022 年度优秀专家称号;公司根据实践经验总结、撰写的《人工智能基础数据业务之个人信息收集活动的合规审计》案例获选中国信通院、中国内审协会“全国首届数字化审计论坛”评选的“个人信息保护合规审计先锋实践案例”。
公司一直坚持安全与发展并重的原则,持续进行数据安全合规能力建设,建立了较强的数据合规体系并积累了丰富的数据合规实践经验,为大模型开展合规训练提供合规保障。
(4)公司实施本项目在经济效益和社会效益上具备可行性
基于谨慎测算,本项目内部收益率高于社会基准折现率,说明项目的经济效益较好,盈利能力较强。本项目生产的产品属于国家鼓励的行业发展方向,能够带动产业链上下游各企业协同发展,具备社会效益。
综上,从经济效益和社会效益分析来看,该项目具备较强可行性。
5、项目投资概算
本项目投资金额总量为 38,337.36 万元,投资明细主要包括场地购置及装修费用、设备购置费用、软件购置费用、数据资源采购、技术人员费用和铺底流动资金。
6、项目实施主体及实施计划
(1)项目实施主体
本项目的实施主体为北京海天瑞声科技股份有限公司及/或下属子公司。
(2)项目实施计划
本项目建设期3年。
7、项目经济效益评价
本项目投资金额 38,337.36 万元,经测算,税后内部收益率为 16.82%,税后投资回收期(含三年建设期)为 5.89 年,经济效益良好。
上述测算不构成公司的盈利预测,测算结果不等于对公司未来利润做出保证,投资者不应据此进行投资决策,投资者据此进行投资决策造成损失的,公司不承担赔偿责任,请投资者予以关注。
8、项目批准情况
目前,本公司正在办理本项目立项备案。
本项目不同于常规生产性项目,不存在废气、废水、废渣等工业污染物,不属于根据《中华人民共和国环境影响评价法》和《建设项目环境影响评价分类管理名录》等相关法律法规需要进行环境影响评价的建设项目。因此,本项目无需进行项目环境影响评价,亦不需要取得环保主管部门对项目的审批文件。








 无锡国家数字电影产业园三期项目可行性研究报告
无锡国家数字电影产业园三期项目可行性研究报告 华侨城文旅装备产业园工程建设投资项目可行性研究报告
华侨城文旅装备产业园工程建设投资项目可行性研究报告 美国亚利桑那州-记忆绵床垫生产基地扩建项目可行性研究报告
美国亚利桑那州-记忆绵床垫生产基地扩建项目可行性研究报告 江西宜春-高能量密度动力储能(方形)锂电池研发产业化项目可行性研究报告
江西宜春-高能量密度动力储能(方形)锂电池研发产业化项目可行性研究报告 水晶光电-台州智能终端用光学组件技改项目可行性研究报告
水晶光电-台州智能终端用光学组件技改项目可行性研究报告 广西钦州-中伟股份北部湾产业基地三元项目一期可行性研究报告
广西钦州-中伟股份北部湾产业基地三元项目一期可行性研究报告 中国天津-毫米波雷达研发中心建设项目可行性研究报告
中国天津-毫米波雷达研发中心建设项目可行性研究报告 中国重庆-国储珞璜智慧物流园项目可行性研究报告
中国重庆-国储珞璜智慧物流园项目可行性研究报告