1、项目背景
(1)受大模型技术驱动,全球人工智能产业进入加速发展期,快速提升大模型相关技术能力成为国家新兴科技发展战略
人工智能大模型因其良好的泛化性和迁移性,有助于推动人工智能进入大规模落地应用,已成为人工智能发展新赛道。同时其强大的理解和生成能力,将驱动人工智能技术加速与实体产业融合,并深刻改变未来人类的生活和工作方式,发展大模型技术成为全球各国比拼科技实力,提升经济效率,拉升经济增长的重要动能之一。
目前,国际巨头纷纷布局以大模型为核心的通用人工智能产业,产业进入加速发展期。在这一信息技术重点领域,我国与国际巨头存在一定差距,正加速布局和应对。国内众多研究机构、企业积极研究生成式AI大模型技术的最优路径,并进行产品发布。近期,在国内科技及投资各领域的高度关注下,百度、商汤、阿里巴巴、华为、科大讯飞、360、京东、字节跳动等企业均有所行动。
我国在“十四五”期间,针对人工智能的未来发展陆续出台了相关指导方案和激励政策,对人工智能的整体发展方向和技术发展重点做出重要规划,同时提出加强算法创新与应用、推动算力基础设施建设、完善数据基础支撑体系等关键建议,倡导未来不断夯实产业发展新基础。
全国各地亦陆续出台多项数据政策,其中,《北京市促进通用人工智能创新发展的若干措施》明确提出要“系统构建大模型等通用人工智能技术体系:开展大模型创新算法及关键技术研究;加强大模型训练数据采集及治理工具研发;建设大模型评测开放服务平台;构建大模型基础软硬件体系。推动通用人工智能技术创新场景应用。
《北京市加快建设具有全球影响力的人工智能创新策源地实施方案(2023-2025 年)》提出“到 2025 年,人工智能基础理论研究取得突破;关键核心技术基本实现自主可控,其中部分技术与应用研究达到世界先进水平;人工智能高水平应用深度赋能实体经济,促进经济高质量发展”的目标,并进一步提出了“自然语言、通用视觉、多模态交互大模型等形成完整技术栈;生成式产品成为国内市场主流应用和生态平台”等具体目标。
(2)人工智能大模型正处于产业发展转型关键期,垂直应用面临爆发
在大模型通用性、泛化性以及扩大人工智能应用范围的优势推动下,人工智能加快与各类产业的渗透和融合。人工智能大模型正处于打造商业模式,形成基础设施能力的关键时期,将从通用逐渐走向垂直领域,在基础模型之上的垂直行业应用也有望兴起。大模型在搜索、推荐、智能交互、生产流程变革、产业提效等场景已表现出了较大的潜力。例如,在金融领域,陆续产生了通过构建大语言
模型等解读征信报告、实现交互式智能客服,为金融服务提质增效赋能。目前,国内相关机构及头部企业在深耕通用基础大模型研发之外,同时根据自身产业生态布局,打造垂直领域大模型,触达应用场景落地;其他具备模型自研能力的肩部厂商,亦基于开源模型或海量数据,打造垂向大模型,建立垂直行业的平台生态。
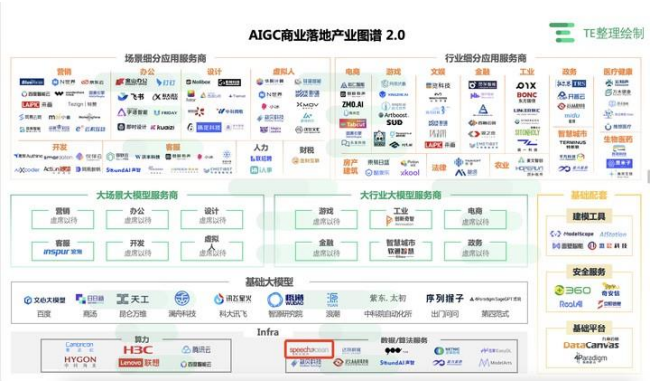
我国 AIGC 商业落地产业图谱如下图所示
来源:亿欧·TE《中国AIGC商用场景趋势捕捉指北》
由于大模型在垂直领域应用场景中,需要依赖垂直领域数据和行业know-how、应用场景和用户数据反哺以及一站式端到端工程化能力等。因此,为实现通用大模型对行业应用的赋能,需要相关领域机构或服务提供商基于通用大模型进行知识迁移,建设行业垂向大模型,实现其纵向业务价值。
(3)大模型对人工智能数据处理技术提出了新要求,该类技术的持续提升是支撑大模型长期发展、持续服务垂直应用的必备能力
目前人工智能进入大模型时代,大规模、高质量数据的重要性愈加凸显,并成为模型训练效果的核心支撑之一,但在数据前沿性及工程化技术方面依然充满挑战。长期来看,AI数据处理技术的持续拓新与发展是及时适应甚至超前引领大模型技术和应用发展的关键。
大模型研发的第一阶段,即预训练阶段,需要通过对海量未经标注数据进行学习,获得"基本的语言能力和通用知识"。虽无需标注,但这一阶段需要对海量数据进行清洗,清洗质量的好坏,会显著影响无监督学习的效果及大模型的精准性。在第二阶段,即强化学习阶段,需要加入人类反馈,人类以标注的方式对机器自学习后的判断进行调整,使得大模型的认知和人类认知进行对齐,亦构成大模型带来优质体验感的核心环节。
当前,业界已形成高度共识,即对于大模型训练来说,数据是模型训练质量的重要保障和核心要素。若要训练一个功能全面的高质量大模型,不仅需要持续获取大规模、高质量、多模态、多场景、多垂向的数据,更需具备持续迭代的高质量数据筛选、清洗等技术和指令、对齐、标注等策略,以不断提升包括预训练阶段、强化学习阶段中所需数据的质量,确保通用能力及各垂直应用能力的提升,为大模型精确性、通用性及泛化能力的实现奠定坚实基础。
2、项目基本情况
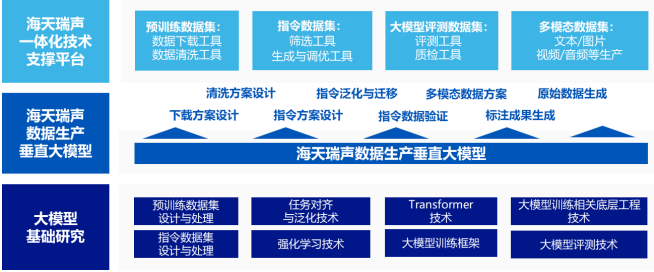
本项目建设目标为研发海天瑞声数据生产垂直大模型,并以海天瑞声数据生产垂直大模型为核心,升级海天瑞声一体化技术支撑平台。
大模型所需数据不同于传统有监督学习范式下的数据需求,数据规模量级大,且近年随着数据安全环境快速驱严,数据使用权限和范围受到更多的限定,因此大模型时代下的数据处理规则将显著区别于传统方式。此外,由于大模型训练数据本身具有更高的复杂性和多样性,其数据服务规则的设计难度也将指数级提升。
因此,为更高效高质完成数据规则的规模化生产,公司将采用全栈自研的数据生产垂直大模型技术,辅助完成面向多个下游任务的数据设计与处理规则,形成下载方案设计、清洗方案设计、指令方案设计、指令泛化与迁移、指令数据验证、多模态数据方案等多项生成能力,以及在上述方案下的原始数据及标注成果生成能力。
同时,为更好实现数据生产垂直大模型下的各类生成能力,公司将研发并引入预训练数据集设计与处理技术、指令数据集设计与处理技术、任务对齐与泛化技术、强化学习技术、Transformer技术、大模型训练框架技术、大模型训练相关底层工程技术、大模型评测技术等,夯实数据生产垂直大模型构建的基础。
此外,基于数据生产垂直大模型的核心能力,项目还将升级海天瑞声一体化技术支撑平台,使其能够全面拥有大模型范式下的数据服务能力。通过嵌入预训练数据下载工具、预训练数据清洗工具、指令数据集筛选工具、指令数据集生成与调优工具、大模型评测数据集评测工具、大模型评测数据集质检工具、多模态数据集生产工具等模块,完成大模型的数据获取与处理工作,打造模型训练、模型评测的能力。
海天瑞声新一代基于数据生产垂直大模型的数据服务技术架构图
3、项目建设必要性
(1)本项目建设是公司落实国家科技创新发展战略的重要举措
人工智能是战略性新兴产业的重要组成部分,对我国经济发展和提升国家战略安全具有重要意义。在世界政治经济格局加速重构的影响下,未来逆全球化趋势仍将延续。全球产业合作格局重构、国际分工体系全面调整,关键环节的国际竞争将加剧,我国在关键核心技术上的问题愈发突出,战略性新兴产业的产业链安全稳定存在潜在隐患。
因此,我国需要进一步集中优势资源,在重点领域加快突破一批关键核心技术,助力提升我国新兴产业的产业链关键环节、关键领域、关键产品的安全保障能力,保障国家战略安全。
公司是我国人工智能数据服务领域的龙头提供商,本项目以研发数据生产垂直大模型为核心,并基于该生产大模型对数据集生产的强大支撑能力,升级海天瑞声一体化技术支撑平台,持续以自主可控的技术与平台为我国人工智能技术与产业发展提供支撑。本项目的建设是公司落实国家科技创新发展战略的重要举措。
(2)本项目建设是巩固公司的核心技术壁垒,构建长期技术实力的必然手段
随着人工智能从深度学习阶段走向大模型阶段,对训练数据服务产生了新的需求,具体可分为预训练阶段和强化学习阶段:在预训练阶段,模型所需的数据量巨大;在强化学习阶段,模型所需的数据质量较高,并需要以相关领域 know-how 作为模型输入。此外,随着多模态大模型的不断发展,跨语音、文本和视频图像数据等多种类别的数据集需求将快速增加。
数据集生产能力和一体化技术支撑平台是公司核心技术的重要体现。目前ChatGPT 等模型执行通用生成任务的效果证明了大模型可具备数据生成能力。本项目的建设将基于公司在深度学习阶段数据集生产所积累的 know-how,自主研发数据生产垂直大模型,构建大模型数据处理技术通用化解决方案能力,实现完整、可持续迭代的大模型数据技术框架和数据策略,进一步提高公司在人工智能基础数据服务领域的智能化水平,巩固公司的核心技术壁垒,形成长期技术实力支撑。
(3)本项目建设是提升公司数据服务综合竞争力的有效途径
大模型训练数据集的生产流程包括设计、获取(模型生成)、清洗、标注、安全管理、质控评测等不同的环节。系统化的开发平台和专业化的软件处理工具对应对大模型时代的数据处理需求和全流程支撑至关重要。本项目有助于进一步优化公司的数据处理技术,促进数据资源处理经验的进一步沉淀,长期来看,可以大幅提高公司的数据处理能力、效率,提升服务范围和水平,适应人工智能发展的新阶段,获得有效长期的发展动力,进一步巩固和提升公司在数据服务领域的竞争力。
4、项目建设可行性
(1)本项目建设符合政策要求和行业发展趋势
2023 年 4 月 11 日,国家互联网信息办公室公布《生成式人工智能服务管理办法(征求意见稿)》,文件明确指出,“国家支持人工智能算法、框架等基础技术的自主创新、推广应用、国际合作,鼓励优先采用安全可信的软件、工具、计算和数据资源”,“用于生成式人工智能产品的预训练、优化训练数据,应满足法律法规要求、不侵权、同时保证数据真实性、准确性、客观性、多样性等若干要求。”该办法从政策层面对生成式人工智能的数据集提出了明确的合法、合规、合理、准确以及知识产权清晰的高要求。
但目前国内大模型的发展普遍存在数据来源不均衡、数据更新实时性弱、垂直类型数据不足、指令集质量欠佳且存在偏见等问题,由此导致大模型的效果、效率、合规性、合理性等方面亟待完善与提升,且在大模型持续发展过程中,部分问题的影响可能持续扩大。因此,建立一套完整、完善、可持续迭代的大模型训练数据技术框架和数据策略,符合生成式人工智能技术与应用合规、高效发展的趋势。
(2)公司与现有客户、科研院所联系紧密,可确保项目技术框架明确、技术路线可行有效
公司自 2005 年成立以来,始终致力于挖掘行业客户需求,解决客户痛点,通过在智能语音、计算机视觉、自然语言等领域的技术积累,获得全球众多客户认可,截至 2022 年底,公司累计客户数量已达到 810 家。公司现有客户包括阿里巴巴、腾讯、百度、科大讯飞、海康威视、字节跳动、微软、亚马逊、三星、中国科学院、清华大学等全球主流企业、教育科研机构以及政企机构。
公司部分现有客户是当前大模型领域的积极实践者,通过与客户的长期合作,深度交流,能够第一时间获取大模型研发中数据痛点与需求,并可在持续交流反馈中不断修正本项目的建设方案。此外,公司也与科研院所和高校等开展深入合作,可引入外部专家资源,以保证技术路线的可行性。
(3)公司拥有深厚的技术沉淀和人才储备,具有完成本项目的技术基础
公司深耕行业近 20 年,拥有一支高素质的研发团队,公司高管及核心研发人员大多毕业于清华、北大、复旦等一流院校,大部分曾在微软、阿里巴巴、英特尔、IBM、中科院等业内领先的成熟企业与研究机构担任人工智能领域技术研发与管理的领导职务。截至 2022 年 12 月 31 日,公司研发人员达到 82 人,经验丰富的技术团队为本项目的执行提供了人才保证。
截至 2022 年底,公司拥有算法模型框架 16 个、算法模型数量超过 200 个,公司自然语言理解算法支持包括语义理解、情感分析和意图识别等能力,语音识别算法支持语种 58 个,计算机视觉算法支持几十大类、上百小类的物体识别。公司在智能语音、自然语言、计算机视觉领域均有多年算法积累,该等算法模型能够全面支撑公司多个领域数据生产活动的开展。
5、项目投资概算
本项目投资金额总量为 40,651.64 万元,投资明细主要包括场地购置及装修费用、设备购置费用、软件购置费用、研发人员费用和设备托管费用。
6、项目实施主体及实施计划
(1)项目实施主体
本项目的实施主体为北京海天瑞声科技股份有限公司及/或下属子公司。
(2)项目实施计划
本项目建设期3年。
7、项目经济效益评价
本项目是公司落实发展战略,顺应行业发展趋势,支撑公司加速数据服务领域算法能力建设、持续构建 AI 产业核心竞争力的必要手段。本项目不直接产生效益,项目建成后将成为公司主营业务长期发展的技术底座。
8、项目批准情况
目前,本公司正在办理本项目立项备案。
本项目不同于常规生产性项目,不存在废气、废水、废渣等工业污染物,不属于根据《中华人民共和国环境影响评价法》和《建设项目环境影响评价分类管理名录》等相关法律法规需要进行环境影响评价的建设项目。因此,本项目无需进行项目环境影响评价,亦不需要取得环保主管部门对项目的审批文件。








 无锡国家数字电影产业园三期项目可行性研究报告
无锡国家数字电影产业园三期项目可行性研究报告 华侨城文旅装备产业园工程建设投资项目可行性研究报告
华侨城文旅装备产业园工程建设投资项目可行性研究报告 美国亚利桑那州-记忆绵床垫生产基地扩建项目可行性研究报告
美国亚利桑那州-记忆绵床垫生产基地扩建项目可行性研究报告 江西宜春-高能量密度动力储能(方形)锂电池研发产业化项目可行性研究报告
江西宜春-高能量密度动力储能(方形)锂电池研发产业化项目可行性研究报告 水晶光电-台州智能终端用光学组件技改项目可行性研究报告
水晶光电-台州智能终端用光学组件技改项目可行性研究报告 广西钦州-中伟股份北部湾产业基地三元项目一期可行性研究报告
广西钦州-中伟股份北部湾产业基地三元项目一期可行性研究报告 中国天津-毫米波雷达研发中心建设项目可行性研究报告
中国天津-毫米波雷达研发中心建设项目可行性研究报告 中国重庆-国储珞璜智慧物流园项目可行性研究报告
中国重庆-国储珞璜智慧物流园项目可行性研究报告